1. The Athens Project - A Proxy Server for Go Modules
Abstract
Go 1.11 introduced modules, the new standard package management system for Go. It’s a massive step forward for the community, especially because we can build proxy servers instead of just using Github to fetch code. Athens is leading the way to solve some painful problems we’ve had for years.
Description
Go 1.11 was a big release for all of us because we got a new package management system called modules built right into the go CLI. There’s some really useful stuff in modules, but there’s one piece that a lot of us missed that we need to pay special attention to: the download API.
We used to download dependency code directly from GitHub, and that led to major problems for the community over time.
The download API lets us fix those problems in an elegant way. We can now build module proxies that save code in their own storage, and Gophers can fetch modules from them without changing much in their workflow. Even better, we can serve those modules to Gophers from CDNs to speed up their builds everywhere. The Athens project is leading the way toward this new world, and it’s a huge step forward for our community!
In this talk, I’ll start with some history of the twists and turns we’ve taken to get to modules, and talk about the problems we still face today. I’ll talk about how Athens solves these problems and how it works, and of course, I’ll show live demos along the way of Athens in action.
You’ll walk away understanding why module proxies and Athens matter, what this new technology actually fixes, how it makes your life easier, and how you can start using Athens right away with very little work.
You’ll also learn why you might want to set up your own Athens server and how to do it. And as an added bonus, after this talk you’ll be able to delete your vendor directories and break out of the GOPATH if you want to!
Notes
I’ve had Go package registries and proxies on my mind for the past few years, and prior to modules I prototyped a few proxies. When Russ released the first vgo prototype (the first protoype of modules), I was excited to see the new download protocol. Right after I saw vgo, I wrote the vgoprox server. It was a simple proxy to which you could point the vgo CLI to, and it would store and serve cached modules from disk.
I shared vgoprox with a few fellow Gophers and we banded together to create the Athens project to continue our work on the proxy. Since then, we’ve built the Athens community to over 50 contributors and 1200+ stars on GitHub - and growing fast. We’ve released a beta and multiple organizations are using Athens in production & contributing, including the Go team for their build farm. We’re also working with global proxy server providers - JFrog and the Go core team right now - to make sure that Athens can talk to upstream proxies from any deployment.
Modules and module proxies are quickly becoming standard in the community for codebases. The Go team announced in late 2018 that they’ll be providing a global module proxy and JFrog will soon be releasing their global proxy.
As organizations evolve their codebases, they’ll need to understand modules and module proxies. This talk is an introduction to those two technologies and equips and encourages Gophers to get ahead of the curve and adopt them now.
I’ve successfully given similar talks on Athens and module proxies at smaller conferences and meetups. Audience members tend to get very excited specifically about the pains that proxies solve for them, and that they don’t have to change their workflow much.
I won’t require any financial assistance to come to this conference.
2. Global Search: Efficient Searching over Multiple Domains Using Go
Abstract
Building a real-time, app-scaled, high concurrency search system using Golang spanning across varied domains like food discovery, location, events, e-commerce etc in a super app using spell-correction, supervised intent classification, NER & smart ranking to surface the most relevant results.
Description
Search has always been an interesting and hard problem to solve, it becomes even more of a challenge with humongous and heterogeneous search space. We at Gojek serve huge traffic on multiple services out of which search is the most common use case. About the scale, Go-Jek serves about 300k requests per minute(100k on Global Search) and these requests span across all the products. The total number of orders that we do currently is well north of 3 million, and out of all these orders about 80% of the orders come through search.
We started with the idea that solving the search problem is going to be the only challenge but figured that high concurrency can be a challenge in itself. We got into CPU and memory related issues (10 calls per user request at 200000 requests per minute) at our scale. Golang came to the rescue and we were able to pull this through with just two modestly configured VMs.
This talk is going to focus on the challenges we faced building a search system on heterogenous space at high concurrency using Golang.
Advantages of spell-correcting search queries over just using a fuzzy match
Using NER to augment search query to be able to discover content beyond simple text-based matching
Probabilistically classifying the search query using supervised machine learning into relevant domains
Problems that we faced with plain vanilla indexing on Elasticsearch and how we went about encoding documents to optimize reads
Ranking the search results within same & cross domains
We don’t have to search in every domain for each query. How we surface results with optimal resource utilization?
Communicating with multiple systems concurrently to serve consistent data at scale
Notes
Technical Requirements-
Familiarity with distributed search systems like Elasticsearch, Solr and basic idea about Golang will help
We have been working on search systems for quite some time now and it is hard to build a one solution fits all kind of thing because users search in very different ways. We have tried to build a system which gives relevant results for a majority of the users and it has worked well for us.
If this talk gets selected, I will be presenting it with another member of my team [redacted]
Ever heard of Microservices? Why is everyone talking about DevOps? Want to understand the relationship between them? Want to learn about DevOps tools?What role does Go play in this entire ecosystem? Should I be investing in learning Go?
Attend this talk to get answers to such questions and lot more!
Description
Description of the Talk
Go for Microservices and DevOps! Yes, I wanted to be a little creative with the title of the talk and hence the pun is intentional.
Here, I will be focussing on the following three main entities:
1. Go language (Obviously)
2. Rise of Microservices architecture in software development
3. DevOps Toolings
Go is undoubtedly skyrocketing in its popularity and there are multiple reasons for it. The obvious ones are as follows:
1. Backed by the big giant - Google
2. Open source programming language
3. Built for speed
4. Easy to learn, read and write
5. The list can go on …
Parallely, we have also been hearing a lot about a popular software architecture pattern - ‘Microservices’. This has dominated the way we design, architect and develop most of our applications and softwares. In addition, it has also laid the foundation for a lot of DevOps tools. The popular ones being Docker and Kubernetes.
This talk is about connecting the above dots, i.e.,
1. The relationship between Microservices and DevOps
2. Go for DevOps tools like Docker and Kubernetes.
The key aspect of the talk will be in understanding the transition of software development cycles towards Microservices architectures, the connection between Microservices and DevOps, the popular tools for DevOps and my personal experience working with some of these tools and most importantly what role has Go lang played to become the defacto language for building such DevOps tools like Docker, Kubernetes, Brigade, Nats and so on.
Outline of the Talk
The Past, Present and Future of Microservices (5 minutes)
Relationship between Microservices and Devops tools like Docker and Kubernetes (5 minutes)
Personal Experiences: (5 minutes)
a. Learnings gained by working with DevOps tools like Docker, Kubernetes, Brigade, Nats and so on
b. Why I started to learn Go language?
How Go became the defacto choice for building DevOps tools? (5 minutes)
Question and Answers (5 minutes)
Intended Audience
Software Developers: People who have been developing softwares and applications but want to understand the importance of Microservices and DevOps tools in the product development cycle
DevOps Engineers: People who have been using DevOps tools but want to understand the importance of Go language in the ecosystem
Go Enthusiasts: People who want to or have started learning Go language and interested in contributing to open source projects and becoming part of those amazing communities
Take Aways from the Talk
Understanding of the entire hype about Microservices
Connection between Microservices and DevOps
Awareness about some of the popular DevOps tools
Motivations/Reasons to learning Go language
Awareness about the different open source projects and communities working with Go language
Relevant Links
[redacted]
Notes
Why am I excited about it? Why should I be the one talking about it?
I work with a lot of companies and startups on various aspects of product development.
As a front end developer, I have had experience of migrating large scale web applications from Angular JS to React JS. Alongside this, I have also had hands-on experience in revamping client side components using material design language for enhanced user experience. In addition, I have even worked on building a web framework from scratch. All these experiences have led me to give a talk in one of the biggest conferences in India - ReactFoo, sponsored by Facebook. [Talk Link] (redacted)
As a backend developer, I have worked with multiple clients globally on several JS, Python and Go based applications and services and gained some insightful experiences of building large scale products with efficient software architectures. Some of the applications include assessment product for learning and hiring using Python and JS, AI chatbots and products in the field of Medical and HR Management, alerting pipeline with centralized error logging for web applications and services using Go language. One of my other talk proposals as a backend developer. [Talk Link] (redacted)
As a cloud infrastructure engineer, my recent engagement has been about rationalizing and scaling the software infrastructure of Rapido - Indian leader in bike taxi service which has 1500+ customers every hour from cities spread across India and 300+ instances of all their services on VM. Some of the product engineering challenges that I had solved during this engagement included containerisation of their critical services, data modelling, developing container based CI/CD pipeline, event based scripting for Kubernetes, streamlining their engineering processes and orchestrating their new container based infrastructure.
In this entire journey, I have gained a lot of experience working with cutting edge technologies and popular languages to build large scale applications which I would love to share it with the community.
4. Why would anyone embed Javascript into the Go app? (we do)
Abstract
Golang is nice, fast and static, everyone knows that. Why would you even want to embed Javascript into that perfectly tuned Go machine?
I’m going to tell how we process data with the rules written in Javascript in our Go app (and it works surprisingly fine).
Description
On the first sight, the idea of interpreting Javascript inside your Go app seems to be bad. But sometimes you need to store in your config files not only values, but some logic. You can invent your own “domain specific language”, but it’s not the easiest and cheapest option.
And we already have Javascript, don’t we?
I’d like to tell how we built a proxy that formats and normalizes data from many different sources with the rules written in Javascript. Every rule is automatically tested, so any of our managers or contractors can write their own rule and be sure that it will not break anything.
This short talk is for intermediate Go developers. I want to encourage everyone to make experiments and prove that strange idea is not always bad.
Notes
My name is [redacted], and I’m from [redacted]. Last 5 years I’ve been working in Travelpayouts.com (part of Aviasales.ru), building our affiliate network with Ruby, Python, Golang, JS etc.
I maintain my own OSS project [redacted] and it’s used now widely in our company.
I was dreaming of going to your conference as a speaker since last year and I did few things for that. I’ve been practicing in public speaking for that: had a talks on two Python meetups in Bangkok in October and January. Here’s a video of my talk [redacted]
I never been a speaker on a serious conference like yours, so I’ve prepared my talk already and I will be presenting it [redacted]. My plan is to have a feedback, impove my talk, add something more and finally have that talk on your conf.
UPD: Here’s my talk at meetup [redacted]
[redacted]
Thank you for organizing such aт event and hope to see you on conf!
5. Centrifugo – building language-agnostic real-time messaging server in Go. And one more Centrifuge.
Abstract
In this talk I’ll highlight some unique features of Centrifugo and tell how Go language helped to build server that is fast, reliable and simple to use. I’ll describe the concepts of new real-time messaging library for Go which is the core of Centrifugo and how it can be helpful for Go developers.
Description
Centrifugo (https://github.com/centrifugal/centrifugo) is a real-time messaging server written in Go. In short: it keeps persistent connections from your application users, manages subscriptions to channels and has an API to publish new events to channels to instantly deliver them to subscribers – i.e. this is a user-facing PUB/SUB server. It allows to build various types of real-time apps – like games, chats, live charts and statistics etc – using Websocket or SockJS transports.
In this talk I’ll tell about some core Centrifugo concepts that allow it to be language-agnostic – i.e. integrate with application written in any programing language. Will describe how Centrifugo solves problems almost every real-time application needs to solve. We will also look at internal building blocks, scalability concerns and protocol decisions.
Centrifugo v2 is built on top of new library for Go language called Centrifuge (https://github.com/centrifugal/centrifuge). The library is also supposed to be general-purpose solution to be used by other Go developers. The part of this talk will be dedicated to this library and its possibilities.
Notes
I started working on Centrifugo 6 years ago so have a pretty good knowledge on real-time messaging topic. Especially in context of web applications.
Centrifugo server is used in several projects of Mail.Ru, in Badoo, Spot.im etc. It’s built on top of great libraries such as Gorilla Websocket, Redigo, Protobuf (Gogoprotobuf), sockjs-go, viper. I believe that new v2 version brings some cool and unique features especially with separate library as core component.
An article about Centrifugo v2 and Centrifuge library on Medium: [redacted]
6. Implementing Observability and Understanding The Data
Abstract
Incorporating observability is difficult to get right. The ability to understand your application while it is running is a critical component in production and all too often ignored. I show how I implemented observability, the benefits and how to understand the data, an often overlooked part.
Description
Incorporating observability into your application is difficult to get right. The ability to understand your application while it is running is a critical component of production ready applications and it is all too often ignored. This talk will show how I implemented observability into my applications and the benefits I and my teams have gained from the engineering effort. I will also share the tooling I used to understand the data, which is a piece most teams miss if they implement observability.
I believe monitoring and observability is usually an afterthought when most developers design and architect applications. Too many developers take for granted their ability to understand how their applications are performing in production and how to fix them when there are problems. By the time they realize they can’t, it is too late. What I am going to share with you is the experience I gained while implementing observability techniques into different applications over the years. I will also share the technical aspects and philosophies I learned along the way including how to understand the data that is being captured.
Incorporating observability principles and techniques into your application is difficult to get right. Once I am done with this talk I will have shown examples of how I have implemented observability into my services. Also I will have shown you the benefits I and my teams have received using these techniques and the tooling I have used to understand the data that was captured. Having the ability to understand your application while it’s running is critical and requires engineering decisions early on in the architecture design. If your application is missing observability or you have not been successful in the past, I hope what I will share with you today will help.
Notes
The target audience are beginner and intermediate developers who build services and want to learn how to incorporate observability into their applications. These are developers who tend to have services already in production and are struggling to manage, debug and learn how to improve their applications.
How many times did you try to decode a string and couldn’t because it was malformed?
With state machines, we can dynamically decode malformed or incomplete strings.
This talk will discuss how to implement such state machines and the problems you might encounter.
Description
Applying university computer science to real projects is not always a straightforward process. This talk is an example of how to implement a finite state machine (FSM) from a paper design to a Golang project.
It all started with a bunch of malformed b64 strings that couldn’t be decoded by standard tools only because they had some invalid characters in the middle. After stripping a couple of them manually, it was time to solve this problem more definitively. Our use case was the decoding package of an open source suite to test web applications, Wapty (https://github.com/empijei/wapty). It then became a standalone tool: https://github.com/AnnaOpss/smartDecode
The smart decode tool uses a finite state machine to parse strings and intelligently decode them. If an invalid sequence is encountered, the tool will replace it with a default character and then try to recover the decoding process. This is possible thanks to a FSM that peeks the next characters and, if they are valid, proceeds to decode them, otherwise ignoring them and moving on.
Notes
This is an outline of the talk:
- What is a finite state machine? And why is it useful to decode strings?
- It all started from BurpSuite decode function. It was not working most of the times because the string was not valid..
After reading the Go documentation, I started a brief project to analyze a string and then decode it in valid chunks.
[redacted] but it wouldn’t accept different encodings and was not usable for more than one codec. This problem sounded a lot like one I had during an exam at the university about a finite state machine.
- Design a finite state machine on paper
- How could I put that nice little drawing in a Golang file? Design the structure of the functions needed: every arrow is a function and every block is a state in a switch case. [redacted]
- Practical example on how that works.
This talk is a demonstration of how Golang can also be used to solve problems of all things ranging from Machine Learning and Algorithms to general Scientific computing. My goal is to inspire Gophers to practice using new data analysis and visualization techniques in Golang.
Description
The most fundamental aspects of data analysis involve using Machine Learning and Visualizations. I want to help Gophers and Cs educators use data visualization libraries that I developed to understand data and make interpretations in a better way. I will use Tensorflow Golang and Gorgonia for Machine Learning , Glot (for Plotting) and Dataviz(For Data Structure Visualizations).
Notes
I think this talk is very appropriate for GopherCon because it touches on good principles and practical experience with the language in a professional environment, and shares a fun focused application of those principles. This will be an example driven talk.
I will show two non related visualization examples
1. I will demonstrate plotting of standard mathematical functions in Golang in both 2-D and 3-D format and also highlight how the ability to be able to visualize data is super conducive to understanding it.
For doing plotting, I will be using [Glot] [redacted] because I wrote it. After making and explaining a few plotting examples I will move on to doing a simple machine learning example using Tensorflow Golang or Gorgonia. The main reason I like Tensorflow Golang is that I am the author of [Tensorflow Ruby] [redacted] and I was heavily involved with the development of Tensorflow Golang and I understand that project really well because I watched it develop from scratch since 2016. I may also use a few other scientific computing packages like Gonum as helpers for my work and then after performing the computations in Tensorflow Golang, I will visualize it with Glot to establish an examples that highlights the importance of performing data analysis.
2. Next, I will move on to a another aspect of Golang that would be extremely helpful for CS educators in the future. As a software developer one of my most important realizations is that the skills I developed from understanding and implementing data-structures had many positive cascading effects on my career as a developer. But another interesting realization while trying to learn algorithms was that it was super hard and required a ton of external resources. I feel a lot of empathy for new programmers who are trying to learn algorithms and I decided to offer something to make their lives far more convenient. So I decided to write [Dataviz] [link redacted] which is a data visualization tool that helps us visualize and understand super complex data structures like Red Black Tree, BTree and others with Golang. So Dataviz is like your average algorithms library with the added ability to make super pretty visuals so that at any instance you can actually visualize your data structure and watch it grow/shrink. Not only this, if you were to navigate through its source code you will find it super easy to understand the logic thereby making it a great tool for students.
9. Let's Learn to build DApps in Go because Blockchain Is The Future
Abstract
The talk will introduce Tendermint and cosmos SDK. Which elegantly hides the complexities of building an App on blockchain and allows developers to get started fast and focus on building great DApps.
Description
Introduction
Tendermint Tendermint Core is Byzantine Fault Tolerant (BFT) middleware that takes a state transition machine - written in any programming language - and securely replicates it on many machines. In other words, a blockchain. Tendermint core takes care of all the low-level layers of the system. As far as developers are concerned they just have to build an application that communicates with the tendermint-core via an API. This API is called Application Blockchain Communication Interface(ABCI).
Cosmos-SDK is an npm-like framework to build secure blockchain applications on top of Tendermint. It can reduce the friction in bootstrapping a new project and will allow us to incorporate third-party plugins to our apps securely.
Always curious and [redacted] at Hashnode, written a lot of Go in the past 2 years. I’ve been playing with tendermint and cosmos for while and working on some cool stealth products on top of them.
I’m not a seasoned speaker but gave my first talk at [redacted] but the videos are not out yet. It was more or less about the same topic.
10. Scaling Machine Learning Application and Data Science Team at Gojek with Go
Abstract
Gojek services are powered by machine learning models served as microservices written in Go. Find out why and how Gojek uses Go programming language and other lessons we have learned to scale machine learning application and data science team.
Description
Introduction
As a super app and Indonesia’s first unicorn, Gojek decides which driver to ‘allocate’ and which food to ‘recommend’ millions of times each day. These decisions are powered by machine learning models served as microservices written in Go.
Go enables Gojek data science team to move faster and autonomous on deploying performant and high-quality machine learning models to production.
Find out why and how Gojek uses Go programming language and other lessons we have learned to scale machine learning application and data science team.
Outline
Early days
Golang, I Choose You
Lasso, A Machine Learning Orchestrator
Omakase, A Machine Learning Framework and Orchestrator
Experimentation
Logging
Conclusion
Early days
The first deployment of a machine learning application in Gojek was a stand-alone machine learning model and web service. This model-was deployed to production within weeks-broke new ground for the company and delivered large business impact.
However, it soon became clear we could do better. A single ML model struggled to balance multiple business objectives. As Gojek grew, we need to develop more machine learning models to support more services, cities, and countries.
Golang, I choose you
Previously, we use Scala and Java to serve our model serving app. But the data science team found it’s harder to manage and the learning curve is harder for junior data scientist.
Finally, we choose Golang as the primary programming language to serve our machine learning models mainly because of the learning curve and it’s easy to read and understand Go’s code.
Other reasons are:
- Built-in testing and profiling framework
- Concurrent
- Low memory
A junior data scientist only needs less than a week to understand the basic of Go. True story.
Voila! Now we have multiple models deployed to production.
But, it became difficult to handle, track, and maintain different versions of the model. Not forget to mention, experimenting with new models was never easy before.
Enter Lasso
Lasso is our microservices orchestrator. Lasso makes HTTP calls to multiple microservices that fetch features or wrap the models responsible for the actual business logic, which we can implement in the most suitable language for the task. Lasso’s workflow and defaults in case of failure are defined using YAML and Go templates. This makes it easy to add additional models as new business objectives emerge. Lasso also handles the logging of each request and response critical for evaluating and debugging model performance. (More on Logging later)
But we still have some problems:
- Redundant codes between each machine learning application. We should be able to reuse them
- Added latency for calling other microservices
- Managing many small services is hard
Enter Omakase
Omakase is a framework and orchestrator for data science team to build and serve machine learning model.
Omakase has 3 main components: recommendation engine, retriever, and ranker. The recommendation engine will act as the orchestrator. From a given query, the recommendation engine will get configuration and decide which retriever and ranker to use. The retriever retrieves items from the database that stored the result of offline computation of the machine learning model. We can say that for each machine learning model, there’s a retriever for a particular model. Finally, the ranker will rank a list of items from the retrieval engine.
Retriever and ranker are Golang interface that can be easily implemented by the data science team to create their own retriever/ranker.
Experimentation is crucial to evaluate the performance of the machine learning model. We have Meister to aggregate the outputs of the different machine learning models, using goal programming to optimize our multiple business objectives. Meister also manages our A/B testing framework and provides flexibility in configuring which models to apply in given locations, at different times, and even for different customer segments.
Logging
Logging is a simple thing but in some cases, it’s hard to do. Especially when we are logging big data. Logging can slow our application down.
We built ds-logging using Go, a system that allows us to log large volumes of data without impacting performance. Typically it is used to log requests and responses to a service. The system consists of library and worker service that logs the data to Google Pub/Sub, Stackdriver, and forwards it to BigQuery where it can be analyzed.
The advantages of ds-logging are:
1. Easy to use.
2. Fast performance.
3. Send log to Stackdriver.
4. Send log to BigQuery, so you can query and analyze the logs.
5. You can monitor your log metrics.
Conclusion
Building a machine learning application is easy, but scaling is hard. Scaling the team behind it is harder. The iteration and incremental feedback are needed to grow together as a team.
Go helps us scale Gojek machine learning products and data science team. Building and scaling performant and high-quality model serving app to handle million of requests is possible because of Go capabilities.
Go also enables our data science team to move faster and give more impact at scale.
“Ok Google, Tell me how do you work?” Have you ever wondered, what goes behind asking a voice assistant to perform a particular action to having the output being delivered to you? Using open source NLP libraries in Go like Prose, we will learn concepts that form the heart of conversational AI.
Description
Conversational AI has found its way into modern day applications and is being extensively put to use in the form of chatbots, voice assistants etc. This talk will throw light on the essential concepts that drives a conversational AI chatbot or voice assistant. The aim is to show the process behind a chatbot taking as input a natural language query, inferring it, deriving actionable insights from it, and finally, acting upon the users request to provide him what he wants. Through this talk while going through the essential concepts, we’ll actually learn how to build a chatbot in GoLang and customize it according to our needs. All the examples for the talk will be in GoLang, using the open source libraries like Prose, Getlang, go-eco, Go-NLP etc for NLP . We will learn about the various concepts while building a chatbot through the duration of the talk. At the end, we will compare the various libraries for NLP in go acc to the features they provide. By the end of the talk, we’ll have a working conversational agent ready to be deployed and that too in GoLang! The talk will focus on the following subsections:
How do these conversational agents work? Here we’ll talk about the pipeline - Sensing the environment, Making decisions, Acting on them.
What enables these agents to sense human language? This will focus on NLP concepts namely Part Of Speech Tagging, Named Entity Recognition, Dependency Parsing, followed by their demos using the above mentioned libraries in Go.
Expanding the scope of knowledge, and Resolving ambiguous entities: How do conversational agents do that? Here we’ll talk about the importance of domain knowledge and context and how we can extract it using open sourced knowledge graphs like Wordnet or Wikidata.
Acting on user intents. Here we’ll focus on how actions are carried out by the conversational agents with coded examples.
We’ll conclude the talk by comparing the various open sourced frameworks and tools for NLP in Go, like Prose, getlang, go-eco to name a few, and see how one can use them for the above learned concepts.
By the end of the talk, we’ll have a working conversational agent ready to be deployed and that too in GoLang!
Learning Outcomes: The working of a conversational agent right from sensing information, grasping the intent, and acting on it, will be explained by using Prose library in GoLang. Processing of Text, Part Of Speech Tagging, Dependency Parsing, Named Entity Recognition, and Disambiguation using Knowledge graphs along with their demos using respective libraries in GoLang.
Making code faster is exciting, and benchmarks in Go make that easy to do!
Not really. Optimizing a program can be complex and require careful consideration to do properly. This talk will demonstrate techniques and tools which are a must for any performance aficionado.
Description
As a Go developer since 2014 interested in performance, I’ve made the mistake of optimizing code the wrong way countless times. From micro-optimizations that don’t affect real performance at all, to optimizing before profiling, to even making code slower without a clue.
And this is because performance optimizations can be fun, but they’re much more complex than one may initially assume.
First, we’ll cover when one should consider optimizing a program. And if so, how one can find the best and easiest pieces to optimize within the program. We’ll ask multiple questions, such as “is this program fast enough?”, and “why is this program slower than expected?”.
Then we’ll cover the first steps to actually optimizing code: writing a benchmark and using it to measure whether a patch actually makes our code faster or not.
This is where the common knowledge among Go developers starts getting thin, so the major takeaways for the audience will likely begin here.
The first major takeaway is that modern machines are complex and unpredictable. Benchmark results can vary wildly due to the machine not being idle, throttling, turbo boost, and many other factors. We’ll show how to keep the variance low with perflock, and how to increase confidence when comparing results with benchstat.
We’ll also show how to measure improvements in memory allocations, not just run-time. This will be a rather simple addition to the last section, as we can reuse benchmarks with the same perflock and benchstat techniques discussed.
The second major takeaway is how to optimize a program when the bottleneck is neither CPU nor memory allocations. Whereas earlier sections would mention pprof, this section will cover trace with some examples where the bottlenecks are blocked goroutines, goroutines fighting over system resources, and so on.
The third and final major takeaway are performance “gotchas”. Broadly speaking, this is when a developer makes an assumption on why a program is slow, or has an idea on how to make it faster, but the results end up saying otherwise. This will include:
how factors like branch prediction, cpu cache, and code alignment can alter performance in unexpected ways
how higher-level code can be faster than hand-written code, if the compiler is smart enough
how adding goroutines may slow down a program depending on its bottleneck
The presentation will also have a final section where general tips and tricks will be showcased. For instance, internal compiler flags to show where nil checks and bounds checks are being inserted, to see if any are being placed in critical loops or functions. We’ll also include some links to extra information, such as Damian’s go-perfbook and multiple blog posts on performance in Go.
You’ll notice that this talk won’t focus on algorithms, nor on common techniques to speed up certain kinds of programs. These aspects of optimizations are more language-agnostic, so I believe it’s far more important to cover the tooling and tips which are specific to Go.
I’ve given over twenty meetup talks and a handful of conference talks at this point, so I’m confident that I can organise the sections into a presentation within the allotted time. As explained above, the presentation would be split in five parts - an introductory section, the three “major takeaways”, and the final “gotchas” part.
Notes
I’ve submitted it as a regular talk since I’d like to have enough time to go into technical details. But if there’s not enough room, I can squeeze most of the content into a lightning talk.
If the talk gets accepted, it would be a great way to push for better official documentation on this topic; see https://github.com/golang/go/issues/23471 which I opened last year.
What is production readiness? How does it relate to your Go app(s)? How important is it? Join two engineers from InVisionApp, as they answer those questions and share their experience as they worked through load testing, GameDay’ing, circuit breaking, tracing and other bulletproofing strategies.
Description
Your new application has made it to production. It’s serving requests and all is well. You don’t have anything to worry about because Go was the perfect tool for the job. With comparatively little effort and boiler plate, Go enables engineers to create fast, scalable, concurrency-driven services in a way that puts many languages to shame.
But is your job done AFTER the application is written? How can you know if the service you wrote is up to snuff? How long is too long to respond? How fast is too fast to fail?
Join Jeff and Dan who will share their experience of bullet proofing their tier 1 services at InVisionApp in order to be able to (comfortably) take on production level load.
During this talk, we will we identify how you can further enhance the performance and reliability of your app(s) by introducing concepts such as load testing, GameDay’ing, circuit breaking, tracing and more.
As an added bonus, we’ll leave you with a “top five things that any Go app running in production should have”.
InVisionApp provides a design collaboration platform for startups, corporations, and design agencies. InVision’s core backend services are written in Go.
Notes
This talk will be presented by two engineers from InVisionApp’s edge team. This team is responsible for a total of 8+ tier 1 services written in Go, that are used for auth(c/z), API aggregation and routing purposes.
We would like to share our experience going through a production readiness initiative that specifically focuses on services written in Go - what worked, what didn’t work, what was difficult (and maybe not so beneficial) and what was easy AND super useful.
Well socialised Gophers often cite readability as one of Go’s core tenets, I disagree.
In this talk I’ll discuss the differences between readability and clarity, show how to write clear Go code, and argue that Go programmers should strive for clarity, not just readability, in their programs.
Description
In this talk argue that clarity, not readability, should be one of the core tenets of Go.
discuss the differences between readability and clarity, show how to write clear Go code, and argue that Go programmers should strive for clarity, not just readability, in their programs.
Outline
Discussion of readability
The most common complaint when faced with a codebase written by someone, or some team, else is the code is unreadable, but readability as a concept is subjective. Readability is nit picking about line length and variable names. Readability is the hand to hand combat of style guides and code review guidelines.
Clarity, on the other hand, is the property of the code on the page. Clear code is independent of the low level details of function names and indentation because clear code is concerned with what the code is doing, not just how it does it.
Through three case studies I will explain the difference between clear code and code that is simply readable.
Case study, declaration
Go has many, Rob Pike would say too many, ways to declare variables.
The limited syntax of Go provides us with half a dozen different ways to declare and optionally initialise a variable.
x := 1
var y = 2
var z int = 3
var a int; a = 4
var b = int(5)
c := int(6)
Which should we use to improve the clarity of our code?
The answer to this question comes down to the intent of the declaration, are we declaring a variable which will be assigned later, or are we declaring a variable with a specific value?
When declaring, but not initialising, a variable, use var. When declaring a variable that will be explicitly initialised later in the function, use the var keyword. The var acts as a clue to say that this variable has been deliberately declared as the zero value of the indicated type. To the reader, it is clear that that responsibility to assigning this variable lies elsewhere in the function (hopefully not far from its declaration)
When declaring and initialising, use :=. When declaring and initialising the variable at the same time, that is to say we’re not letting the variable be implicitly initialised to its zero value, use the short variable declaration form. This makes it clear to the reader that the variable on the left hand side of the := is being deliberately initialised.
Case study, selection
Structured programming provides us with three control structures; sequence, selection, and iteration.
We should write Go code in a way that does not obscure the flow of control in a program as this is key to reasoning about the program itself.
Example, guard clauses
Go programs are traditionally written in a style that favours guard clauses, preconditions.
This encourages the success path to proceed down the page, rather than be indented towards the right.
The canonical example of this is the classic err check idiom; if err is not nil, then return it to the caller, else continue with the function.
We can generalise this pattern a little, in pseudocode we have
if <condition> {
// cleanup
return
}
// success
If the precondition failed, then return to the caller, else continue towards the end of the function.
This general condition holds true for all preconditions, error checks, map lookups, length checks, the exact form of the precondition’s condition changes, but the pattern is clear, the cleanup code is inside the block, terminating in a return, the success condition lies outside the block, and is only reachable if the precondition is true.
Even if you are unsure what the preceding and succeeding code does, how the precondition is formed, and how the cleanup code works, it is clear to the reader that this is a guard clause.
Further examples that will be covered are long chains of if else, and switch statements with default conditions.
Case study, accept interfaces, return structs
The final case study covers the use of interfaces to describe to the behaviour of the values being passed into a function independent from the parameter’s types, or their implementation.
Constants are my favourite feature of Go. In this talk I’ll explore the amazing properties of Go constants, like
How untyped constants are often taken for granted
How typed constants can hold methods
How to create immutable singletons
& how to create powerful constant error types
Description
Many years ago Rob Pike remarked that “Numbers are just numbers, you’ll never see ULL in a .go source file”. This profound statement is sometimes taken for granted by the Go community because, as Rob noted, numbers–constants–in Go, just work. Behind this pithy observation lies the fascinating world of Go’s constant types.
In this talk I want to explore the nature of constants in Go. How their amorphous nature allows us to write programs without having to consider the size of a memory location that would hold a constant. How typed constants allow types such as time.Duration to perform arithmetic and print themselves. How to create a truely immutable singleton in Go (spoiler, its not a struct). And lastly how to create error values with logical properties far beyond those offered in the standard library while being truely immutable.
Outline:
Introduction
Brief overview of arithmetic between typed and untyped constants, eg.
today := time.Now()
day := 24 * time.Hour
year := 365 * day
fmt.Println("The date for GopherCon SG 2020 is", today.Add(1 * year))
Specifically highlight automatic promotion of an untyped 24 to time.Duration via its multiplication by time.Hour, and the fact that the resulting value is larger than a 32 bit int, yet we don’t need to worry about truncation or specifying ULL as in C/C++
Constants can have methods
The previous section highlighted the power of the interaction between untyped constant literals and typed constants, but more exciting is constants in Go can have types, and because those types are user defined, they can have methods. This gives Go constants amazing properties, like the ability to format themselves while printed
func main() {
const x = 1
const y time.Duration = 1
fmt.Println(x, y) // 1 1ns
}
How to make truely immutable singletons
Now that we have the basics of typed constants down, we’ll use that knowledge to look at a common programming pattern, the singleton, and use constants to make it safer.
The example I’m using is the os.Stdin,os.Stdout,os.Stderr triplet of singletons. I’ll explain why these really are singletons, as opposed to things which Go programmers agree to co-ordinate on using. I’ll explain the problems with their current variable declaration, and show a replacement that makes these singletons truely immutable.
Constant errors
The final example builds on the previous by demonstrating the link between the singleton pattern, and the sentinel error pattern present in many Go libraries (sentinel errors are public package error variables such as io.EOF). I’ll discuss the problems with sentinel errors, including their lack of immutability and fungibility, and show a replacement constant error pattern that delivers the same programming experience of a sentinel error while retaining the immutable properties we expect from a constant.
Conclusion
This talk has shown three ways of using constants in Go that go beyond giving names to magic numbers and I’ll call on the audience to build upon these ideas and write safer and more reliable Go programs using these techniques.
16. Observability and performance analysis with BPF
Abstract
BPF is a virtual machine inside the Linux Kernel that provides secure, and high performant observability. BPF is changing how engineers analyze and observe programs running in production. This talk will challenge the audience to explore the Linux Kernel ways that they never thought possible before.
Description
BPF is a virtual machine inside the Linux Kernel that provides secure, and high performant observability, with minimal overhead. It allows engineers to modify the kernel’s behaviors to certain events without having to build kernel modules or having to recompile the kernel itself. BPF is changing how engineers analyze and observe programs running at scale in production.
In this talk, we’ll explore how to take advantage of BPF to trace Go applications in production, and how the Go compiler makes all this possible. We’ll also talk about how to write BPF programs with Go.
In this talk you’ll learn:
Why BPF is a technology that you want to have in your toolbox for observability and performance analysis.
How BPF gives you deep visibility inside your production infrastructure and your Go applications.
What types of programs you can write with BPF.
Notes
BPF can be very intimidating because it’s a technology built within the Linux kernel. This talk tries to demystify that, and will show examples to encourage the audience to learn BPF. I won’t go into every detail about BPF, because 30⁄45 minutes is not enough, but I’ll leave the audience prepared to dive into the topic themselves without feeling intimidated.
People with some knowledge about the Linux Kernel internals will be more prepared to attend this talk. However, it’s not a hard requirement. BPF programs are written in C, but they are easy enough to understand if the audience has some basic knowledge about the language, or even if they know other modern programming languages like Go.
I’m writing a book for O’Reilly Media titled “Linux Observability with BPF” that covers this topic in high detail. From how BPF is implemented, to how engineers can use it in their day to day.
This could also be a workshop, BPF is a topic broad enough to spend more than an hour talking about it, and people learn better with real code that they can write.
In this talk, I will share about our experience using Go as our first backend language from scratch and how it evolved with the startup.. We will cover range of topics that a founding tech team needs to consider and explore why Go is great for startups and areas where it fall short.
Description
For the lightning talk, I will like to present and share briefly on the following topics from early stage startup perspective (1-5 engineers) and where to learn more.
- General advantages and disadvantages of Go from early stage startup perspective.
- Design (Package structure, architecture, API options such as RESTful, RPC, GraphQL, etc)
- Devtool, frameworks and community
- Build and Deployment
- Monitoring and logging
- Debugging
- Testing
- Concurrency
Notes
I learnt RoR and Go in 2016 in a year-long US internship and decided to use Go to build our startup from scratch from 2017 until now (8 engineers, 4 Go developers).
My talk should be relatable to students, budding entrepreneurs or even veterans thinking of testing the waters with Go for big or small projects of any lifespan. I do not claim to be an expert, in fact I hope through sharing, I get to learn from insights brought forth by attendees of various background and experience.
I have attended GopherCon SG for last 2 years and loved the energy (which is representative of Go community at large) and I finally decided to submit a proposal for this year :)
I am happy to build up more content for a main talk if the committee is interested!
When we’ve huge scale, performance matters, and to reduce the resource consumption. we should look beyond the de-facto HTTP.
We will see why and how gRPC could help us in those aspects.
Description
Why gRPC
A glance of gRPC
will touch upon basics of it, what it could do, RPC, unary, bidirectional, streaming
Protobuf
Though JSON is the contract we’ve used mostly, protobuf is both memory efficient and performant.
Having a common contract, and less pain to deal with versioning
Multiple clients (languages) could be generated easily, its more cool, coz you wouldn’t need any external libs to make HTTP calls, the code looks like a function. (Yeah, its Remote Procedure Call :) )
Streaming
Whether you’ve huge data, you wanna stream (either from client or server), its very easy to achieve with gRPC
When you need a state change (data), to get it instantly if we do poll, it would cause huge load on the servers, rather server push could be treated as an alternative. and with gRPC server push is achievable in a better way than JSON (Simple, not that simple when you’ve a distributed systems)
How you would you know which client (connection) to push out of N (really large) request streams you’re holding.
Server Push
will see a demo of server push (if time permits)
Connections
As said gRPC has active connections held in case of streaming, how do we handle failures? deployment of services, proxy? Imagine millions of connections having file descriptor (connection leak resulting in memory leak) would crash the system. Will talk about how to maintain active connections.
Health Check is a way to achieve this like a heartbeat.
Monitoring, Proxy
Well, in REST world its easy to load balance using proxies, you could have HA Proxy, dns or simpler solutions, when you’ve streaming (active connections), what would happen? How do we load balance it?
will see how to do gRPC load balancing [will look at envoy] (client side discovery and server side proxy)
Monitoring is crucial in any realtime system in business and we need to have alerts on it, to keep in live all time
Notes
Requirements:
Having audience to have basic understanding REST HTTP services would help. (will share the links, so they could read, will be more effective)
Why Me :D
I’ve been working in developing Backend Services, which deals with Huge Scale (on Ecosystem where Millions of transactions happens everyday), seen both good and bad parts of Micro services (literally when one service goes down or becomes slow, unless we’ve circuit breakers you’ll pull down others too), so I’ve been working on system with scale and performance. I could share my learnings in real prod scenario :)
gRPC, we’ve started to introduce in our ecosystem, for server push, I’ve been part of few who spiked and started this. Implementation of gRPC is simple, but to make a theory that it will work in huge scale (active connections) wasn’t easy. Done enough load testing and used envoy for our use case, and we’ve good numbers.
[We might see it in prod before this talk :D so i could share more real prod numbers]
More generic:
- I’m interested in solving complex problems, always curious to share and learn
- golang enthusiast
- Have done some opensource contributions :D [github] [link redacted]
- my work experience [linkedin] [link redacted]
- Go Evangelist & [redacted]
19. Building Scalable Service - Learnings and Gotcha's
Abstract
Building A Restful Service in go sounds easy, but there’s lot of things to watch out for, especially if you have huge customer base and your service is critical to business.
In this talk we will discuss how to build scalable service which fits our need, also sharing the learnings.
Description
How to build a scalable RESTful service, going through the obvious problems like
1. Goroutine leaks (will monitor it with tracing tool)
2. Memory leaks
Complicated ones under huge throughput/load
1. File descriptor issues
2. DB bottleneck
3. Network latency issues
Will discuss about the architecture, different setups and issues in each. why could it not be a single service in a single box, but rather tons of services as MicroServices. Also the baggage of problem which comes along, will see how to tackle and make it work for us.
Will also see how to monitor the scalable service, slightly touch on CI/CD, testing if time permits.
Everything will be mostly explained/shown with code examples.
Notes
i work at Go-jek, where we build services for really huge scale, (though we’ve written different services in different tech stack) i’ve seen the value given by golang, (we scaled down from 100% to 20% boxes for the same load), its performant.
also i’m a golang enthusiast. i’ve talked in golang [redacted] meetups, gave lightning talk in last gophercon.
Ever wondered how a load balancer balances the load, how an ACL routes a request to specific backend, and about replication and sharding?
Then this talk is for you, Will understand how a Reverse Proxy could do Sharding / Replication / Mocking and we can implement those with simpleGo code.
Description
Agenda
Setup quick context on HTTP Server and Request
Echo server, which displays information about request (Demo)
Reverse Proxy
Sharding: forward requests to specific backend based on request
Concepts
Will set basic context and dive deeper in code for explaining the concepts.
Echo Server
We will quickly talk about HTTP Server, Request and middleware. HTTP Server and request information are the basis for echo server, This is in the net/http package.
We will run the echo server, which could be customised to display specific requests (predicate on method, url (regex) or body or a combination). This will enable us to inspect the request.
Reverse Proxy
What’s a reverse proxy comparison with forward proxy. What a reverse proxy could let us do
Load Balancing (across multiple backends)
Caching Requests
SSL Termination
etc.
Code and Usecases
We will write the code to implement reverse proxy to route requests based on request information like url to specific configured backend.
And we will explain few of the concepts, so now its more easy to understand.
Sharding - send requests to specific backend (not random loadbalance but on configuration basis)
Replication - send request to multiple backends
CQRS - Read and write queries routed based on config. read request to read service with slave db, and writes to service with master db.
Authentication, Ratelimit in proxy
Mock Server to send a mock response which’s configured for requests, which can be used at failure times.
The features are useful in distributed services, to handle load, and deals with multiple aspects (replication for failures, isolations (zone based, read/write), sharding to reduce dataset, etc) these concepts applies to db as well in similar way.
Though it might sound complicated the code is super simple, which will also give us basic understand. Code and description is at github mirror (link redacted)
Similar articles or concepts, which you could read before the talk.
I’ve experience with writing production systems in Go, which handling huge load, and performance. We’ve done more infrastructure and architecture optimization to deal with our system better. (loadbalancers, sharding, partitioning, caching etc)
I’m also creating a library to do simple sharding/replication/mock server (load testing, or debugging a dependent service) etc, so i’ve concrete code to show.
Go evangelist & enthusiast, and have been part of the community Co-organsier and gave talks. [link redacted]
Have given a talk in this in recent meetup [screencast] [link redacted] and it evolved from basic and realised its more useful and extendable.
In this talk we have a look at the new Go Modules functionality and explore everything that a user needs to understand to use them, from creating a project, using dependencies, running tests and more.
Description
This talk is dedicated to covering Go Modules in depth.
I will present how Go Modules work, what are the benefits and drawbacks from using them.
I will also show how they work, where they are used, what’s the current state of the ecosystem surrounding them, as well as show how a project can be migrated to use modules.
Advanced uses such as using GOPROXY, the state of Athens, Go Center, and Artifactory will also be shown to users, as well as using Go Modules with Docker (and how the cache can be saved for reuse when using containers.
The goal is to give everyone attending or watching the talk enough information to have them use Go Modules successfully in their day to day life right after the talk.
This talk focuses on the productivity that GoLand can bring to a Go developer.
We’ll explore the ways the IDE adapts to your workflow, how it can help you detect and fix issues, integrate with other languages, all
while keeping the same experience regardless of the platform you are working on.
Description
Code editors are part of our day to day life, regardless of the operating system, programming language, or proficiency with the language.
As such, we expect them to adapt to our workflows, we want them to be smart when they are needed, and stay out of our way otherwise.
This talk will explore how the built-in, real-time, code analysis integrates with IDE and provides contextual feedback and solutions for users. It will also present how the refactoring options allow users to perform operations such as extracting interfaces from types, moving types across packages, and others in a safe manner across large codebases.
Not a GoLand user? Don’t worry; the talk will contain information that should allow you to get started, by showing you how to start with the environment setup, new project and all the way to the commit and push phase. Or it will help you to decide if you want to avoid it altogether.
Are you interested in tooling for Go in general? Then the talk will allow you to see how the IDE perform static code analysis on the Go sources, explain the benefits of the IntelliJ Platform for developing tooling for languages, and provide a different perspective on how Go tooling could interact with code. The presentation will also describe some of the features that make the platform unique.
Notes
The is relevant for all gophers, both those currently using this IDE or those who are not, since everyone benefits from better tools.
However, code editors can be a very tough subject to approach as it can generate a lot of discussions.
This talk will be purely a technical talk, highlighting the features of the editor while steering clear from making comparisons between other editors, casting a bad light on other editors, or promoting this particular editor as a single option for Go programmers.
As an example of how the talk format will be, here is the IntelliJ/Java equivalent: [link redacted]
Learn how to build and manage serverless tools and apps to help you in everyday life in 30 minutes or less.
Description
This talk looks at what are the options available for a Go developer to work in such environments and showcase going from scratch to a full project in less than 30 minutes
I will quickly explain the serverless concepts, the pros and cons for using it, and show examples of when serverless can be used to make a difference.
After that, I will show various platforms for running serverless workloads, such as AWS Lambda or GCP Cloud Functions.
With that knowledge, I will then show users how to build such serverless apps so that they can be ready to migrate from a platform to another with little code overhead.
One last use-case I’ll present is a possible way to architect their apps for the future, where one could move pieces of logic from standard web servers to serverless infrastructure and vice-versa.
If Internet is available (and working), and the Demo Gods are not acting up, this talk will feature live demos, otherwise material will be prepared for off-line scenarios.
Go is seen as a language for tooling and web servers. But can it be used in a Desktop application?
Description
In this talk, we explore this domain, see what tools we have available, state of the art in Desktop development with Go and what’s next.
The talk will start by questioning where is Go used and why.
Then we’ll have a look at the available options which are actively maintained to create a Desktop application.
Following these steps, we’ll dive right in into creating one such application.
The purpose of the talk is to demonstrate that Go can be used in reasonably complex Desktop applications and encourage people to explore more in this direction.
In this talk, we’ll have a look at how to use the popular Raspberry Pi 3 development platform with Go and add some smartness to it to automate our lives.
Description
In this talk, I plan to present how Go can be used on hardware such as RPI3.
I’ll use one of the projects from https://aiyprojects.withgoogle.com/ combined with gobot.io and show how with a few lines of code, you can turn a $50 kit into a smart home automation device.
The goal of the presentation is to enable the audience to have fun while working with Go, create something different, and learn how Go can be used in non-web or CLI projects.
Live coding will be present, depending on the venue capabilities.
26. An investigative walk through of Go's channels
Abstract
Have you ever wondered how Go’s channels work internally? Does the answer to make(chan int, 1) != make(chan int) keeps you up at night? If you would like to see behind the curtain then this talk is for you?
Description
Have you ever wondered how Go’s channels work internally? Does the answer to make(chan int, 1) != make(chan int) keeps you up at night? If you would like to see behind the curtain then this talk is for you?
This talk deeps dive into the inner workings of Go’s channels using an interactive debugger to understand it’s strengths and shortcomings. If you are curious, like me, as to why there are two kinds of channels in Go and the difference in their behaviour, then this talk is for you.
Notes
Technical Requirements: An intermediate level of understanding of Go’s concurrency, have worked with channels and goroutines
I am probably the best person to speak on the subject cause of my curiosity and having worked with concurrency in Swift, Node.js, Rust, Erlang/Elixir, Clojure, Python and Ruby… I find Go’s concurrency model far superior and simple to use. This talk lifts the veil on the inner workings of Go’s channels, which every Go developer needs to be familiar with, but hardly anyone bothers to look under the hood.
Go and Erlang came from the same CSP paper by Tony Hoare on the concurrency front, yet they take different approaches on resiliency and fault tolerance. This talk will shed light on the different approaches and also bring some of the patterns from Erlang to Go.
Description
Erlang comes with OTP and supervisor trees to manage process failures, when a process fails (panics) there are ways in which the process restarts itself. This is without the use of supervisord. OTP based applications have proven themselves to be far more resilient than any other system on this planet. We as Go developers can pick some of the patterns from the Erlang ecosystem using libraries like suture. More importantly we can think in ways to make our applications highly available and keeping downtime to a minimum. We will also briefly touch upon other ways of designing highly available systems using Kubernetes and Kafka.
Notes
I have been developing web based applications since 2012. I have been exploring Go since mid-2014 and Erlang since 2013. In order to be qualified as the best person on the topic, I have developed applications with high availability requirements and have been training people to be able to do the same.
28. Golang Web Development and Its Deployment with Azure DevOps
Abstract
Even though Go web apps was announced to run on Azure App Service in 2015 via Kudu, two years later, the support is discontinued. With the new technology such as Azure DevOps Pipelines and Azure Kubernetes Service, I’d like to share how we can do CI/CD deployment for Go web app on Azure again.
Description
This talk is to share my Golang web development learning journey to build a YouTube Re-Player app which is now running on Microsoft Azure Web App (link redacted). The talk will focus on CI/CD with Azure DevOps (especially Pipelines) + Github, Azure Kubernetes Service. At the same time, I will also cover some useful services offered by Azure, such as Application Insights and how they can be used to make our Golang better on the cloud platform.
This talk will be a good starting point for those web developers who are familiar with Azure but are new to Golang web development and would like to understand how to have a simple web app running on Azure.
Notes
In the Microsoft Ignite Tour Singapore happened in January 2019, Brian Ketelsen asked the audience who had experience with Golang web application. In the room of 300+ developers, I was the only one who raised the hand. So both of us were quite surprised that no one was interested to find out how Golang works in web development field.
Also, inspired by Chang Sausheong’s book “Go Web Programming”, I have been experimenting with different ways to find out how to properly build a web app in Go. Hence, I’d like to take this Gopher Conference Singapore as a chance to encourage, especially those who have been dealing with Azure in their daily work and new to Golang web development, to try out Golang web development.
I’m currently building a web application in Golang and host it on Azure. I also have a [Github repo] [link redacted] for it which I use it to do CI/CD with Azure DevOps Pipelines. It’s still in progress but I hope to finish it by mid of February 2019 so that I can use them as resources to the audience.
This topic will cover how to find security issue on GO code using open source Static Analysis Security Testing. So that developer can found & fixed the security issue since on development stage, without waiting for penetration testing stage
Description
Find vulnerability on development stage should be implemented to find vulnerability on earlier stage (development stage) on Software Development Life Cycle (SDLC). Most of vulnerability found on final stage of SDLC through penetration testing. Security issues were accidentally created on design and development stage, meanwhile developer couldn’t identify the vulnerability because they should wait until application passing through penetration testing, which mean on final stage. If vulnerability figured out by developer earlier, they can realize and fixed the vulnerability without waiting till penetration testing.
Static Application Security Testing (SAST) can be used to find vulnerability on development stage. SAST is a set of technologies designed to analyze application source code, byte code and binaries for coding and design conditions that are indicative of security vulnerabilities”(gartner.com).
This topic will cover how to find security issues on GO code using free/open source SAST.
Notes
so, how this topic is relevant to GO enthusiast audience ? because this topic will cover how to find security issue using free/open source Static Aplication Securtiy Testing (SAST) tools which specially created for GO programming language.
So that, GO developer will be able to find vulnerability on their GO code and make secure code without waiting for penetration test result.
30. Traveloka Data Journey with Golang, GraphQL and Microservices
Abstract
Unique experience from one of the big online travel agent in SEA, Traveloka, in migrating the internal Data Platform from a monolith Java app into microservices app in Golang & GraphQL. This talk also discuss how we use Kubernetes & Istio to efficiently deploy, monitor and scale this system.
Description
This talk speaks about Traveloka Data Platform journey in adopting Golang and micro service based architecture to replace the previous monolith RESTful API Java app which previously is used to provide transactional and behaviour data to other internal services within Traveloka. This talk will discuss how the Golang + GraphQL improves the user experience of our data users to get the data they need for their mission, how we protect those data from the unauthorised access and how the backed service mesh we developed with Golang + Go-Micro can support and provide data to the GraphQL server in front. But, talking about microservices will not be very exciting as it can be unless we are also discuss how we orchestrate those in Kubernetes and Istio. And here we go talking about end-to-end implementation of our data platform system with Golang, GraphQL and Kubernetes.
Notes
In the talk, we are going to explain those following things:
Technical Requirements:
Here is some important requirements for the project discussed in this talk:
* A secured GraphQL API must be used as the interface between the data layer services and the data users. A secured mean that only authenticated users who has enough permission to some data which only can access the system and it’s data.
* GraphQL API must has P95 latency 200ms
* Each data domain should be handled by a responsible micro service which can be scaled independently.
Architecture Decisions
Here is some architectural decisions we made based on those requirements:
* We decided to use gqlgen library (GitHub - 99designs/gqlgen: go generate based graphql server library) as the GraphQL server library. This library encourage us to use SDL-first or Schema-first approach in developing our GraphQL library.
* Go-Micro is used as the micro service framework since it provides us with service discovery, grace client side load balancing, asynchronous messaging with Cloud Pub/Sub, and nice gRPC support for inter service communication.
* Cloud Bigtable used as the main storage for most of the micro services because of its ability to support high throughput request with minimum latency for retrieving huge number of data.
* Auth0 and JWT Token is used as the basic authentication mechanism. In addition, an independent ACL service must be in place to check whether a requesting client has enough access to the data they are interested in, up to certain level of granularity.
* All micro services should be containerised and should be deployed and scaled within our Kubernetes cluster (with Istio installed) within seconds. Kubernetes and Istio provide us a set of features for securing inter-service communication and for monitoring the entire system including distributed trace.
In this talk, we are also going to share the experiences from our developer about Golang (including learning curves we took) and how GraphQL improves the experiences of our internal data user in requesting the data from us.
I wrote a lot of code in Objective-C as an iOS developer, then Swift came along and I had to change my approach to writing code. As you might expect, I had to change my mindset when learning Go. Are Swift and Go really so different? We’ll discuss what I’ve learned on the path to becoming a Gopher.
Description
I wrote a lot of code in Objective-C as an iOS developer, then Swift came along and I had to change my approach to writing code. As you might expect, I had to change my mindset when learning Go. Are Swift and Go really so different? We’ll discuss what I’ve learned on the path to becoming a Gopher.
Notes
These are some video recordings of conference presentations I’ve given, which will give you a sense for my presentation style.
- [link redacted]
- [link redacted]
My GitHub profile has a repo [link redacted] with all of my previous (and upcoming) speaking engagements. There, you can find the slides, source code, and links to Speaker Deck/YouTube/Vimeo where applicable.
Have you ever wondered how games are written? In this talk, we will learn how to write simple 2D games using Go. We will unravel the concepts of the game loop, state management, and audio-visual integration. We will see how Go’s simplicity and type-safety makes writing games in Go to be so much fun.
Description
This talk hopes to cover the basic principles of creating 2D games with Go, using an open-source game library called Pixel. The talk will attempt to explain the basics of creating and managing window, drawing sprites and shapes, and handling user inputs from keyboard/mouse. This longer talk format will also cover some demonstrations of the code being shown, as well as the speaker’s personal projects. If time permits, the speaker hopes to share some tips and tricks for optimizing the performance of your 2D game written in Pixel.
Notes
No pre-requisites necessary for the participants. This is an introductory talk that will explain how the attendees can get started with game programming in Go.
Speaker has a significant experience in building games in general, and with Go. He is a contributor to one of the popular game engines in Go called Pixel and helped with some functions on the underlying audio engine called Beep. He previously built games with Unity and was under the tutelage of the Founder of Bethesda during his college years. Currently, he is working as a full time Go developer, managing large scale payment systems using gRPC, Docker and Kubernetes.
A support for audio for demonstration will be nice to have. If it is not possible, let me know so that I can adjust the content of the talk slightly to emphasize demonstration based on the visual elements.
Call Levels has thousands of users and handles millions of price tracking subscriptions (we call it Levels). This talk mainly discusses the challenges we have faced as we grow and how we use Go and other technologies to solve these challenges.
Description
Call Levels (https://call-levels.com) is an application used by investors to monitor market price. Last year, we were shortlisted as SG top ten fintechs. As Call Levels grow to thousands of users globally, we started to get more and more challenges. This condition forces us to redesign our architecture and build a new solution that can handle millions of price tracking subscriptions. This talk mainly discusses the challenges we have faced and how we use Go and other technologies to solve these challenges.
Notes
As [redacted] of Call Levels, I designed the architecture and lead the team to build the new backend solution for Call Levels app.
This is an example of how a user uses our app:
For example, the current price of USD-SGD is 1.36
A user wants to get notified if the USD-SGD price falls to 1.2
The user uses Call Levels and set a subscription (USD-SGD at price 1.2)
When the real price falls to 1.2, Call Levels will send the price hit notification to the user.
This can be easily solved if we only have a few users and a few subscriptions. As the numbers grow, we started to face challenges like users didn’t notifications, notifications delayed, etc. In the end, our backend solution can monitor millions of price tracking subscriptions, and when thousands of the subscriptions get hit at the same time, we can still send the hit notifications to users in several seconds. As I’m writing this, we still trying to do more optimizations to achieve 1 million concurrent hits and send the notification to users within 1 minute.
34. Setting up a Development Environment for Go with Docker
Abstract
Live-reload, dependency management, and releasing were some of the most difficult things I experienced when starting my journey in Go after years of JavaScript. So here’s how I managed to achieve all the above with Docker so I could get up and writing code as quickly as possible.
Description
Golang is performant, concurrent, and has some nice language semantics. One problem: it’s a pain to get started. GOPATH didn’t play well with other projects in other languages, requiring it’s own /path/to/go/src, dependencies were a hit or miss, and live-reload tools were breaking with the introduction of Go Modules in 1.11.
This short sharing covers issues I faced while switching over from JavaScript, the experience of replicating the developer tooling I had in JS, and a solution I finally came to using Docker; This covers namely: live-reloading of applications and tests, ease of dependency management, organising related services in the same directory (instead of a …/go/src, and a sub-commands based build system.
Notes
No technical requirements needed from participants. I’m speaking on this because of my passion for setting up development environments that enable developers to get up-and-running as quickly as possible - something I also do in my professional duties for my team. Doing this for a profession also (hopefully) means that I think I’d be able to deliver concepts that are applicable to other Golang developers looking to bring Golang into their teams but who may not be able to figure out a quick way to encourage transitioning to Golang from another established and well-tooled language.
Software reliability is often neglected, but is increasingly important. This talk discusses why certain high-reliability software engineering practices exist and how they can be implemented in Go. This talk features real world software failures and describes how such instances can be prevented.
Description
In a lot of engineering environments, software reliability isn’t considered as important as it should be. As general-purpose software becomes ever more critical to our lives, it is important the software we produce is safe and secure. This talk describes how developers can incorporate some High Reliability Software Engineering practices into their workflow to produce better software.
Whilst we already have practices like Test Driven Development, error handling and tracking at our disposal, we can go further and use lesser-known practices to drive improvements in reliability. This talk will cover how developers can encode intentions and requirements in software, using the Design-by-Contract methodology. Further, it will cover how to handle violations and errors in real-time environments, alongside using analysis techniques to prevent defective software being rolled-out. Additionally, this talk will use modern tooling to implement such practices; using Prometheus, Sentry and Continuous Integration pipelines.
This talk will present practical examples of where software has gone disastrously wrong, why such incidents happened and how they can be prevented with examples in Go. Both the why and how of high-reliability techniques will be explored.
This talk will give an overview of RESTful API development in Go. The talk will cover securing API endpoints, storage using Redis/MongoDB, and writing unit tests for HTTP handlers. This talk also goes through some best practices for API development in Go.
Description
Outline:
-Introduction to RESTful API
-Why Go?
-HTTP Methods: GET, POST, PATCH & DELETE
-A simple API endpoint
-Securing API endpoints JWT, CORS
-Data storage using Redis & MongoDB
-Writing unit test for HTTP handlers
-Best practices
Notes
Attendees should have experience in at least one programming language.
I’m a software developer, working in a startup in [redacted]. My tech stack is- Go, Redis, MongoDB. Since I work on the proposed talk on a day to day basis, I’d be the perfect one to respond to their Questions.
After hypnotizing the large scale cloud software community with its capabilities, Gopher now starts to stare at the exciting area of Deep learning. Deep learning in Go? !! But Why? And How? What’s next? Curious? Let’s explore it with a fun-filled, fast-paced Deep dive into Deep Learning in Go.
Description
Golang has emerged as a clear leader when building large scale infrastructure tools and projects. But as one of its next steps next step Go is slowly gaining momentum towards its adoption to Train and Serve Deep learning models. But its current capabilities are not well known. However, the interest in using Go for Deep learning is growing in the community. My talk is to spread awareness and evangelize using Go for Deep learning, understand the current state of the art capabilities, demonstrate how it’s done and what to expect in the coming year.
Notes
I’m the [redacted] at Kredaro, an early stage startup focussed on enabling business transformation and growth through our products and services offering on scale and intelligence. My footprint of contribution in Go community is significant. I’m one of the early architect and contributor to Caddy project (Nginx alternative written in Go) and one of the early engineers at Minio (Silicon Valley company which builds Amazon S3’s open source alternative in Go). Three time speaker at redacted. Authoring Deep learning with Go for Packt publication. Have authored over 275+ blogs, some popular Golang blogs too (For example try Googling for “Debug goroutine leaks”, my blog appears first in the result). In past couple of years I’ve been set out in the journey of building large scale analytics, ML and Deep learning pipelines and adding value to other business through my startup Kredaro [link redacted] .
I believe that with the combined experience of being an Open source contributor in Go, An Entrepreneur, Writer, An experienced fun filled Tech Speaker, A deep learning engineer, and a Musician I would be a unique and valuable addition to the event and audience and possibly one of the best ones to talk about Deep learning in Go.
Gunk is a modern frontend and syntax for Protocol Buffers that greatly accelerates building APIs and services in a way that is native to Go. Learn how to leverage Gunk to rapidly build/deploy microservices in this talk.
Description
In this tutorial, [redacted] will introduce and detail using Gunk, a modern frontend and syntax for Google’s Protocol Buffers that is instantly familiar and accessible to Go developers. Gunk builds on the venerable Go tooling – including versioning with Go modules, and a Go-derived syntax – to create streamlined, project-based workflows for building REST and gRPC services. [redacted] will also give a practical demonstration of using gunk and how it integrates with the greater protobuf ecosystem, including generating Twirp and OpenAPI service definitions and code generation. Learn how to build microservices and build pipelines using exclusively Go based tools. No more protoc!
Notes
Gunk, a tool built at Brankas, has recently released the first version. We have significant plans for its development in the coming months, including a major release that would coincide with GopherCon this year. While the technology is still new, a number of very large banks, insurance companies, and ecommerce companies in Southeast Asia have adopted Gunk and its project based workflows for defining and rapidly pushing into production various services and APIs.
Gunk’s unique contribution is its Go-derived syntax for defining Protocol Buffer messages and services, and looks like the following:
The above has standard Go syntax, but gets translated in a 1:1 fashion with a full Protocol Buffer message. The gunk tool masks most of the complexity and difficulty in building protobuf messages and services.
As the original designer of the technology (all respects and due deference to the original Go creators), I welcome a chance to share with the greater Go community how it’s possible to leverage the Go standard library and toolchain in ways not really thought of before. Gunk is a radically different approach to working with Protocol Buffers, and I believe a new and unique contribution to the Go community.
Code generation is the fifth stage of grief over Go’s lack of generics. With go generate we have a powerful tool to skip writing boilerplate code. Using the ast package I will demonstrate how one file can declare your API, generate middlewares (logging, instrumentation, etc.) and even documentation.
Description
Introduction
Code generation is ultimately the fifth stage of grief over Go’s lack of generics. We’ve come to accept that Go doesn’t have generics (yet!) but we still want to avoid the tedious task of writing duplicate code. In software engineering, code generation is a noble deed in any case. It improves code quality by delegating the task of writing boilerplate code to a machine thus less prone to errors.
The go binary comes with a subcommand called generate which scans packages for generate directives and for each directive, the specified generator is run; if files are named, they must be Go source files and generation happens only for directives in those files, i.e. you would put this line at the top of your file:
//go:generate apigen
This simple mechanism allows for plenty of use cases. In this talk we will explore how we can utilize go generate to generate middlewares and documentation for a HTTP REST API automatically out of a single file using the ast and template packages by writing our own parser. You can appoint a single file to the DSL of your API. Request and response structs and your HTTP handler method will create the internal model of your API. Eventually, this model will be used in conjunction with templates to generate your middlewares.
Bullet Points, Talk Structure
The Five Stages of Grief Over Go’s Lack of Generics
go generate - how does it work?
Writing a parser using the ast (Abstract Syntax Tree) and template package of Go
Generating a logging middleware
Generating all kinds of middlewares (recording API requests, instrumentation)
Utilizing code comments to generate your API documentation
Making it part of your automatic deployment
Conclusion
The design for Go 2 is still on the horizon and we don’t know when and if they will arrive. In the meantime we should utilize the tools we have to be as productive as possible and go generate is a Swiss Army knife kind of tool which is useful to have in your set of solutions if you want to generalize parts of your code base. Introducing your own tools bears the risk of introducing additional code that needs to be maintained. We cannot talk about automation without mentioning the xkcd comic: Is It Worth the Time?
.
It has to be careful considered if it’s worth investing into such a toolchain but especially In the case of an API which is in constant change such a tool can be priceless.
Notes
This talk is for people who have already gained some level of proficiency with Go as I am introducing meta-programming techniques. I am working for a startup in the Bay Area building a social network as a lead architect. As such we are working with an API which is under rapid development processes. I have introduced code generation into our stack and it reduced our development time massively which is why I would like to share the insights I have gained with the Go community.
Enterprise platforms are essential for business operations but should not be intimidating the users. An opinionated custom CLI is a wise investment to the platform for self-serving needs. This talk addresses the importance of building custom CLI to assist end users and how to start developing one.
Description
In large enterprise organizations, we need tools. We need lots, and lots of tools to support customers and developers and operations support. Many times the tool needs to be domain specific, so we can’t easily use off the shelf or open source applications. In this talk, I discuss my team’s journey building such an internal tool in Go, including what we learned, how we built it, and what we might do differently if we had to do it all over again.
Our initial self-service tools were GUI based, super expensive to build, and complex, ever-changing user interfaces created constant friction with consumers. We couldn’t meet our original goal of automating the entire process, so we shifted our focus to building an opinionated CLI for our core platforms to serve as both a self-service tool and a build pipeline component.
Why Go? Go is a modern general purpose programming language, no doubt about it but it was not the single qualifying factor. We built other CLIs in the past; some were based on bash scripts, they were not platform-agnostic, hard to write test cases and often shipped new releases with bugs. The other CLIs built-in dynamic languages faced challenges with language runtime (e.g., python 2.7, 3.6) and dependent libraries (e.g., OpenSSL 2.2.5, 2.2.7) version conflicts in both user and server environment.
Creating a command line application (CLI) and distributing to multiple OS platforms has never been easier than with Go. The developers loved the single binary file requirement for self-service needs as well as guaranteed seamless integration of CLIs with various LOB pipelines. This set a success path in effectively managing core application platforms in Capital One.
In this talk, I’ll share our journey, lessons learned from building enterprise CLI applications and also how to develop CLI application in Go through a series of demos with and without other libraries from Go ecosystem. Key takeaways from this talk include experience and case studies involving platform ownership and satisfying consumers, the challenges involved in building internal tooling (GUI vs. CLI, etc.), and details on how to build a CLI application in Go using the Cobra and Viper libraries.
Notes
The speaker is a Full-stack engineer, specialized in building Microservices at scale, Big Data processing & DevOps automation. His current interest is Golang, building/rebuilding microservices in Go for yielding high performance for real-time decision and fulfillment platforms. He is also a Certified Kubernetes administrator (CKA), AWS developer and SysOps administrator associate. He has worked on multiple core-platforms since last year, improved engineers experience in building CLI for feature-library management, internally hosted FAAS platform and production issue troubleshooting & tracking needs.
This talk will address the importance of building CLI but not limited to simplify production troubleshooting, automate trivial tasks and better developer on-boarding experience to their platform. Developers, Architects and Product Owners of the core platform will understand the importance of improved developer experience and productivity to manage a successful platform.
Step-by-step demonstration with Clean Code in Go with SOLID principles by building simple RESTful APIs and how we apply it while we designing the application architecture and writing the code.
[additional] Some details about Clean Architecture to help us build better applications
Description
Go Clean and be SOLID
Step-by-step demonstration with Clean Code in Go with SOLID principles
In the talk, I will step-by-step demonstrate Clean Code in Go by building simple RESTful APIs.
During the steps, I will explain about SOLID principles and how we apply it while we designing the application architecture and writing the code.
Additionally I will also mention some more details about Clean Architecture to help us build better applications.
Notes
Go is a so simple language that people can pick it up quickly. However the code base can also be messed up very quickly without good understanding about high quality code (a.k.a Clean Code), good application architecture.
Nowadays, it is very important to put our efforts into the developer community to encourage and educate them to build high quality application, starting with clean code and clean architecture.
Many people heard about this, not so many people really understand about this and very little people can actually implement it in reality.
This step-by-step talk is one of my great effort to bring developer community to a higher level, especially for the community in Singapore, Asia, more especially for Go, the language from bottom of my heart!
The Analysis API is used to write analyses (like those in go vet and go lint) that can help surface bugs and show code improvements to users. I’ll show how to use and write analyses, and see their results, so you can help improve your code quality.
Description
“Writing Go Analyses with go/analysis”: Description for attendees
The Analysis API is used to write analyses (like those in go vet and go lint) that can help surface bugs and show code improvements to users. I’ll show how to use and write analyses, and see their results, so you can help improve your code quality.
“Writing Go Analyses with go/analysis”: Details for CPF committee:
Background
We’ve introduced a new framework for writing analyses for Go in the golang.org/x/tools/go/analysis package. “Analyses” are tools that inspect programs and report errors, warnings, or other helpful info. The checks done by “Lint”, “Vet”, “Errcheck”, and “Gometalinter” are examples of analyses. On the Go team, we’ve been working on making analyses easier to write and easier to surface in editors and other useful places. The talk’s purpose is to introduce the analysis framework to the audience so that they will be able to write analyses themselves. These new analyses that the attendees and the community writes might be contributed back to the above tools and help spot problems in and make improvements to all of our code. Or they may be written at various Go-using companies to ensure correct usage of proprietary libraries. In either case, this talk aims to inspire Gophercon attendees to write more analyses (and to show them how easy they are to write!) resulting in improved Go code everywhere!
Structure
I plan the talk to be structured as follows:
Introduce the concept of analyses and what they provide users; give examples of analyses users are familiar with.
Jump into a basic analysis (say one that identifies calls to printf) and show how the analysis uses the API
Go more in-depth into the analysis API and explain what it provides.
The Analysis interface analyses implement and the Pass struct they’re provided, and the difference between “diagnostics” and “facts”
Demo the writing of a simple analysis that checks something simple: for example, that sort.Slice is given a slice.
Demo writing a simple analysis using the API
Show the results of the analysis showing up in an editor through the LSP
Web servers have always been the standalone part of our infrastructure. We have very little control over them and sometimes we forget that many battle tested web servers are written in Go. In this talk we are going to see how to extend our code’s capability by embedding Caddy server as a library.
Description
Gophers know that the CaddyServer is a very simple and secure web server written in Go. One can configure it and deploy their app within minutes. But do you know that it can be embedded to your code by importing as a library? Yes, this allows us to tightly couple a battle tested secure web server as a reverse proxy or a load balancer to our code. This will help us in many use cases. In this talk we are going to see how we architected a solution to scale docker instances by spinning up new instance and dynamically proxying it on demand through CaddyServer for every login session in web app.
Outline (20 min)
Introduction, Reverse proxies and CaddyServer (5 min)
Embedding the caddy server with graceful restarts (3 min)
Proxying new endpoints dynamically using Go templates (2 min)
Architecture of the docker scaling use case (5 min)
Demo: Scaling docker instances with embedded Caddy Server (5 min)
Takeaways
How to embed a web server into your Go code
Architecture of the embedded web server setup for docker-scaling use case
Bonus: how to use docker client as library in Go code
Notes
This talk is intended for intermediate audiences who knows a bit about architecture design, docker and web servers, but it’s not compulsory. I will try to make it as simple as possible.
I am currently consulting for Bay Area based client where I design, build and deploy their backend infrastructures. The above mentioned problem is something which I faced recently and solved it for them using Docker, Go and an embedded caddy server. Sharing the experience during from the project would help others take better architecture decisions and also they will learn something new like running a web server/load balancer from Go code. I am a frequent speaker at Python Conferences and organizer of [redacted] Golang meetup [link redacted].
Related articles from me which was featured in Golang Weekly:
1. [redacted]
2. [redacted]
44. (Adapting) AI enabled ways to scale workloads on Kubernetes
Abstract
In the session, we will walk through how we developed AI enabled modules for finding the ideal metrics and predictive horizontal pod autoscaler for kubernetes. The last piece is a set of add-ons. With the help of these controllers, it is possible to apply any deployment templates for above scenarios
Description
Google Kubernetes Engine service offers fully-managed Kubernetes clusters with enterprise-grade support from Google that makes it easy to start deploying containerized applications. However, deploying an application by no means make it production-grade.While GKE makes it easily to deploy containerized apps, it is still non-trivial to make them highly available and use auto-scaling to maximize availability of your services.
When making Kubernetes applications highly available, there are two major steps you need to take: utilizing multi-zone availability and use time-series metrics monitoring with a tool like Prometheus. As hundreds of custom metrics are collected by Prometheus, finding the right values and metrics for autoscaling is manual and requires human judgement. Utilizing AI is possibly one of the most revolutionary methods to derive auto scaling recommendations from metrics. Our first AI based module finds those custom auto scaling metrics by monitoring the load on the deployments.
Despite using the custom auto scaling metrics is at administrator’s preference, it is still possible to improve the whole responsiveness of the system. Our second AI module uses the outputs of the first module to analyze the history of auto scaling metrics of Kubernetes deployments to better schedule the pods. Thus deployments can be pre-scheduled before reaching the thresholds of custom auto scaling metrics. This will help you proactively meet the increasing system load.
In this session, we will walk through how we developed these AI enabled modules for finding the ideal metrics and predictive horizontal pod autoscaler.The last piece is a set of metacontroller add-ons. With the help of these controllers, it is possible to apply any deployment templates for above scenarios.
After this talk, you will feel comfortable in applying some innovative ways of autoscaling your Kubernetes workloads.
Notes
[redacted] is a Googler and lead of our project at the customer site. We will present this session together.
What are Containers and How is Docker made? It’s a bunch of namespaces and cgroups put together to build the process isolations that we see. What are namespaces and how do they operate? The talk invokes one Linux namespace at a time, as system calls from a Golang code, up to a full-fledged container
Description
Docker, RKT, LXC by now are pretty pedestrian pieces of technology that any DevOps candidate is supposed to know. But what most end up overlooking is the rudimentary technology that is used to build these containers.
While covering namespace and cgroups are beyond the scope of a single talk,
1. I would like to cover various Linux namespaces with an in-depth demonstration of how a running system interacts with processes and namespaces.
2. The communication is done using simple Golang programs which make System calls to invoke and switch namespaces of a running process.
3. I would like to talk about mount hierarchies, the elegance of /proc/self/exe.
By the end of the talk, attendees will be able to understand:
1. How namespaces are implemented and operated in Linux systems
2. How simple Golang code can be used to run sophisticated tasks
3. understand what runs under a container
Notes
The talk assumes an understanding of the Linux and basic Linux commands. It would be ideal if the audience members have some hands-on experience with running services in production. Though it’s not mandatory.
I have been an Infrastructure engineer for over a decade now before it was called DevOps. I have had some good and bad learnings throughout my career, and this talk is a means to share them.
46. My TLS exchange was broken, and probably yours too.
Abstract
So you have a cross-server-talk and you secured it with TLS. Can your server tell that one of the Certs was revoked? Can it tell that a cert has expired? The talk covers the journey of TLS, how languages (even Go) fail or refuse to do this for you. And how do we go about addressing this?
Description
TLS has come a long way and probably one of the least discussed topics in public Talks.
The talk will walk through understanding Certs, how server-to-server TLS exchange happens. What is CRL and how do you detect Revocation Lists. Problem with CRL lists? What is OCSP and how does it solve the problem of CRLs. What is the problem with OCSP? What is OCSP Stapling? Why languages do not address the problems of identifying revocation and expired certs. How do we bring this all together to bring an actually trustable server to server exchange?
While the topic is applicable to all Languages and not just Golang in general, We will implement the problem statement in Golang that span the following stages:
Create a simple TLS TTP Server
Create a simple TCP TLS Server
Introduce Certificate Revocation
The inability of default TLS Exchange to continue to detect these easily.
Introduce a CRL Listener.
Introduce OCSP and OCSP Stapling.
Introduce an OCSP handler.
Introduce mechanisms to detect revocation.
Birth of CFSSL.
Introduction to Catoolkit, an open-source framework we have implemented to tackle this problem.
Reaching your own PKI
Through the journey of this code demonstration and walk-through, the focus is on the simplicity of Golang and how the language by design allows us to tackle a substantially complex problem without getting in the way. We will also stress on the design of complex software done Incrementally and mostly how Golang allows this. The cost of design-patterns is too cheap.
The key takeaways from the talk are:
- Understanding of TLS.
- Understanding how complex functionalities can be wrapped in simple Golang codes.
- A deeper understanding of some of the untalked-about Golang libraries.
Notes
The talk is a consortium and regurgitation of my learning of TLS through these years. By no means, Am I a security expert and nor is this a silver bullet of solving problems. It’s just an understanding of TLS as a problem and as a solution, both.
More and more businesses are moving from products and services to subscriptions. We discuss key challenges in building a subscription engine and why we chose Go. We focus on immutability, orthogonality, and idempotency as the core building principles and how we incorporated them with the help of Go.
Description
In this talk, we explain how we built a subscription platform from scratch using Golang with a focus on reliability, availability, debuggability, and scale. You will learn about some of the key points to consider while building a subscription engine and how some of Golang’s out of the box features help with this. If you are an engineer/architect working on building subscription platforms, this session is for you.
Notes
Over the past few years, we’ve built a subscription engine at Viki using which we have multiplied our monthly and annual subscriptions. As the lead engineer for the project who was actively involved in this project from the beginning, I shall speak about our motivation for choosing Golang to build our engine, and how Go proved to be a good fit to match our requirements. I shall also discuss some of the key challenges and issues we faced and key takeaways.
Writing Microservices which can withstand the unpredictable nature of the production environment at scale is a non-trivial task. Certain practices can help make our systems more predictable, transparent and resilient. For developers this means more confident and continuous deployments.
Description
Microservices are trendy and everyone is talking about it. Deploying microservices which can withstand the unpredictable nature of production is hard. It needs a certain level of discipline. One of the biggest challenges for organisations that have adopted the microservice architecture is operational and architectural standardisation. In this talk we discuss a checklist of things to keep in mind when taking any microservice live in production. We discuss things learned in making systems more predictable, observable and resilient.
This talk is for everyone who wants to be confident in taking services live in production more frequently with less failures.
Notes
We will answer some of the following questions in the talk:
How Standardization of certain practices is the key for continuous deploys with less downtimes ?
Discuss the need for introducing Production readiness checklist in GO-JEK
How to implement this checklist in Go microservices ?
Discuss checklist items like building Observability, Canarying, Runbooks, Rollbacks etc
How this standardization has helped GO-JEK developers be more confident when deploying ?
Having worked with distributed systems at scale with high uptime requirements at GO-JEK, most of these patterns/practices are learnt the hard way. The talk will be culmination of all my experiences in building these systems at scale.
This talk will cover the motivation behind, implementation of, and future plans for gopls, the Go implementation of the Language Server Protocol. This tool is currently being developed by the Go team and Go tools community, and it will ultimately serve as the backend for any LSP-compatible editor.
Description
The Go community has built many amazing tools to improve the Go developer experience—gocode, gogetdoc, goimports, guru, gorename, the list goes on. When these tools are maintained and discoverable, the Go coding experience is seamless. However, when a maintainer disappears or a new Go release wreaks havoc, the Go development experience becomes frustrating and complicated. This was particularly obvious with the release of Go Modules, which broke every Go tool (see: the parallel existences of nsf/gocode, mdempsky/gocode, and stamblerre/gocode).
As a response to this, the Go tools team developed the go/packages API, which makes it simpler to write tools for all build systems. gopls is built on top of this API, and it implements the Language Server Protocol (https://microsoft.github.io/language-server-protocol), which has now become the industry standard for editor integration. gopls centralizes a significant portion of Go tooling functionality into a single binary. A caching layer speeds up all functionality, and Go users are spared the indecision and banality of choosing individual tools for basic features, like autocompletion and formatting.
This talk will cover the basic background of Go tooling and provide justification for the development of golsp. It will also cover the fundamentals of the design, ranging from topics such as writing tools that work on broken code to effectively testing Go tools.
The talk will be of interest to tool writers of all levels, as well as anyone hoping to begin working on Go tools or editor integrations. This talk will also interest Go users generally, as many people may not be familiar with the details of their Go editor setup and might wish to optimize their environment. Learning about gopls will increase user awareness of the available tooling, and the ultimate goal of this talk is to help users code more effectively in Go.
I am one of the engineers working on gopls, along with Peter Weinberger and Go tools team manager, Ian Cottrell. I have been on the Go tools team for 2.5 years, and I have worked on a variety of Go tools, including gocode, guru, and several other Google internal tools.
TinyGo takes the Go programming language to the “final frontier” where we could not go before running directly on microcontrollers like Arduino and more! TinyGo (http://tinygo.org) is a new miniature version of the Go language that can run directly even on the smallest of computing devices.
Description
TinyGo takes the Go programming language to the “final frontier” where we could not go before… running directly on microcontrollers like Arduino and more! In this talk I will introduce TinyGo (http://tinygo.org) a new miniature version of the Go language that uses the LLVM compiler toolchain to create native code that can run directly even on the smallest of computing devices.
This talk will feature live coding demos of flying objects…
51. Controlling Distributed Energy Resources with Edge Computing and Go
Abstract
With advancing technologies, energy distribution model has changed from being centralised to being distributed. We created a platform for distributing and running IoT apps, written in Go, on edge devices to monitor and control distributed energy resources such as photovoltaic and battery systems.
Description
The energy distribution model in the 20th century is that of centralised generation with large power plants fuelled by coal or gas, and distributed through a centralised electricity grid. But much of that has changed, with advancing technologies diversifying the grid, adding new sources of generation through distributed wind and solar generation. Homes with solar photovoltaic (PV) panels and home battery systems, smart meters and demand response are also changing the way we consume electricity.
In this talk we will be describing how we created an IoT platform that is already running production in a number of sites all over Singapore, to monitor and control such distributed energy resources (DER). We will also talk about how this platform is used to distribute IoT apps, written in Go, that can be run on edge devices.
We will discuss how we structure our IoT apps that allow us to interface with different types of distributed energy resources and adapt to platform changes as it evolves. Finally, we will discuss why Go is our language of choice to write the IoT apps.
Designing a client package for API server is a little harder than designing normal packages.
With an actual package I created, I’ll show you how to develop a secure and extensible API Client which can keep up with the interface changes quickly and achieve enough test coverages.
Description
Creating a client package for API server is a little harder than developing normal packages. If you are to create it just for a few endpoints, it won’t be that hard because what you have to do is only to write a simple method to call API with net/http.
However, it’ll be hard to create an API Client which call a lot of endpoints and the I/F changes frequently. Because you have to both keep up the I/F changes and consider for users who use nested structs and fields defined in your package. And of course, you also need to pay attention to test coverages of methods with integration/unit testing.
This talk is about all of these topics to develop maintainable, and easy to use API client in Go with the actual package I designed.
I’ll also touch upon topics like code generation, AST parsing, symmetric API testing, how to define an interface which supplies non-stressful user experience, and integration/unit testing specialized for API Client.
Notes
The followings are the agenda of this talk:
Self Introduction (1-2 mins)
The basis of API Client (3 mins)
API Design of API Client (6 mins)
Unit/Integration Testing API Call (9~10 mins)
1. Self Introduction (1-2 mins)
Only a self introduction.
2. The basis of API Client (3 mins)
An introduction of a simple API call, and the difference between developing a simple client and developing a complex, always changing, an easy-to-extend client.
3. API Design of API Client (6 mins)
In this section, I will explain how code generation and AST parser enforce you to design a user-friendly client.
- null-guard: When you design API client, you have to mind how it is non-stressful to use with null-guarded structs.
- code generation: go generate and a template helps you to create null-guarded accessors on DRY Principle.
- AST Parser: Scanning the whole code of your client, AST parser gives you a resource for code generation.
4. Unit/Integration Testing API Call (9~10 mins)
API client is a little hard to test because an ideal way to test them is actually calling the target API but you can’t.
Symmetric testing is recording API response to take care of the stress of a target API.
In this last section, I will introduce unit and integration testing with symmetric testing for developing a secure API client.
What can you get from logs of HAProxy?
What if I tell you, with correct tools you can mining “silver” or even “gold” from HAProxy logs?
In this talk we will see how to use haminer with TICK stack to mining HAProxy logs to get live preview of our API and aggregating it for analytics.
Description
In this talk we will see how to use haminer with TICK stack to mining HAProxy logs to get live preview of error in our API and aggregating it for analytics (for example, computing API success rate for SLI to be reviewed by SRE).
haminer is a library and program to parse and forward HAProxy logs. haminer require a database to save the logs from HAProxy. Currently supported forwarder (or database) is InfluxDB.
Notes
The draft for this talk is available for preview at [redacted] .
Everyone know and use slice, but how well we really known the behavior of slice when pass it to function or sub-slicing it? With their power, slices have their “gotcha”. What are they? By knowing slices and their “gotcha” we can write better program or may take advantages of it.
Description
The first question is why “Slices”? There are two final points that I will make in my talk: to avoid possible “gotcha” and to take advantage of it.
My talk consist of reviewing slices again from beginning, its contains exercises to let viewer learn by doing. In the beginning, I will talk about array, and then continued by “what is slices”. I will give an example what would happened when we pass slice to function, when we modify slice in function, when we sub-slicing slice, when we modify the sub-slice.
After viewer understand the behavior of slices (passing to function and sub-slicing), we continue to review possible problems with it. One is slice reallocation the other is unreleased memory due to slicing.
The draft for my talk can be viewed at [redacted].
55. Mastering Maps and Location data: Tools and Workflows
Abstract
Maps are cool and location-tagged data is widespread - How does one get started with processing, visualizing and interpreting such data using Go? We show how simple Go libraries, concurrency, and browser-based maps are helping Fastah shine new light on an old problem: mobile internet performance.
Description
Who am I ( 2 minutes )
[redacted] Fastah, data networking expert, builder of maps - network latency maps
Previously WebKit.org open source contributor for Symbian OS
What do we build and Why ( 3 minutes )
We are building Google Traffic, but for 4G LTE speeds on consumer mobile networks - 80 cities, 12 carriers in SE & S Asia
Why does it matter? It shows good and bad internet zones down to a city block
Network weather changes all the time: We help “gig economy” workers be online more reliably via an app
We help (micro)mobility businesses such as e-bikes, e-scooters and ride-sharing predict and react to network changes via APIs
YOUR takeaways from this talk (2 minutes)
Exploring geo-tagged data with Go
Building usable CLI tools, and embracing UNIX philosophy with decomposition & pipelines
Visualizing geo-tagged data with your browser
Moving models from the exploration phase to production ready
Exploring data and Scrubbing it with Go [5 minutes]
Data scrubbing and validation is a critical part of exploratory problem solving
Fastah’s latency maps of the mobile internet require a lot of parameter tuning and data scrubbing
We have embraced JSON-LF and CSV for text-oriented and schema-less data expression
Unix pipelines and problem decomposition: CLI tool design to make intermediate data debuggable
Bonus: an easy path to production-scale deployments with the right use of Go concurrency
Putting it all on a map [4 minutes]
Embracing GeoJSON, the text-oriented geodata standard
Using browser-based map providers (Mapbox, Google Maps) to visualize GeoJSON data
JavaScript + HTML5 + GeoJSON : a powerful trinity
Examples of colourful latency maps for Singapore, Jakarta and Mumbai!
Libraries and Tools we recommend: Part I [5 minutes]
Highly recommend Orb (github.com/paulmach/orb)
Orb: Implements primitive operations such as intersect, contained-in etc on points, shapes and lines
Orb: Provides idiomatic Go APIs to marshal and unmarshal GeoJSON data
Orb: Implements SQL scanners when you are ready to adopt schema/structured databases (think Postgres+PostGIS)
Orb: Demonstrate example code for geographic “search” and “contains” operations
Libraries and Tools we recommend: Part II [5 minutes]
Mapbox GL JS: modern JavaScript/HTML5 interface to a powerful mapping platform.
Easy to start using with GeoJSON - overall, a low learning curve for newbies to GIS
Easy to style and theme maps
Access to CLI tools to improve develop-debug-deploy cycles (github.com/mapbox/mapbox-cli-py)
Postgres with PostGIS: SQL database with native support for GIS operations - when you are ready for production + schemas
Summary [2 minutes]
Go, the Orb library and JavaScript APIs to Mapbox make it easy for newbies to become GIS practitioners!
Notes
I am [redacted] at Fastah, where we build Google Traffic-like speed maps for 4G LTE networks in Asia. We crowd-source network latency data from a few hundred thousand smartphones every month (running on 12+ carriers in 80 Asian cities), and this talk speaks about our journey exploring data networking using Go tools, but with a geospatial point-of-view.
What are Fastah map’s use cases? Just like Google Traffic’s APIs help Grab, GoJek and, Uber dispatch taxis efficiently, Fastah’s network performance maps are used via APIs by businesses to optimize urban mobility (eBikes, eScooters, taxis) and device “uptime” of their on-demand field workers.
We have been using Go for 4+ years and have had a chance to go “We are just exploring data” to “This needs to work in production at scale!”. We recently presented Fastah’s work to the Internet Engineering Task Force’s pre-Bangkok meeting to a vigorous discussion: [link redacted] .
In this keynote, we story-tell how we used Go’s command-line philosophy, geodata libraries such as Orb, the GeoJSON standard, and Mapbox-like JavaScript map frameworks to transition from geodata newbies to competent practitioners.
56. Go Connection Management: What is a Lesson Learned?
Abstract
A while ago, KBTG developed a system for one of the largest live EDM concerts in Thailand with Go. A chaos began when our system started to slow down, and eventually it went down completely. We were baffled. We will share our experience on how we investigated the problems and what we came up with.
Description
Due to a rapid move towards a cashless society in Thailand, we are developing several cashless payment solutions. One of which is cashless payment via a wrist-worn device, which enables new payment experiences that are not only secured but extremely convenient. Our backend services for this payment system are implemented using Go language.
In the past, we had an event that requires us to handle http connection in real time response, targeted to be 200 TPS. Few hours later, our server went down without any clues, our server seemed fine. Then, we found that the open files in Unix exceeded the limit. By taking times to look in our code we found that there was a code to call to mongoDB but did not close the connection. Consequently, any functions that call this method will leave the connection unclosed. We had to fix this problem and deploy immediately, and then everything seemed fine after that.
The solution we come up with is to manage the database connection inside the middleware. Once the program starts, the DB middleware function establishes a new session to a database cluster. Then, the DB middleware function returns the handler, which performs the session clone and close, to be added to the middleware stack. The benefit of this approach is that the database session is entirely and automatically managed by the middleware. Hence, it is certain that database connection leaks are prevented since the database session of all services is properly handled at one place. However, there are some drawbacks to this approach. Since the database session management is performed inside the middleware, sessions of all databases are cloned for every incoming request even though some services do not require those connections. Consequently, excessive overhead is incurred.
To prevent accidental connection leaks from opening database connections, the database session management is completely handled by the web middleware. However, this is achieved at the expense of inefficient use of system resources.
This talk is on building an automated pipeline(CI/CD) to production hosted on Google Cloud by taking advantage of golang language.
Description
DevOps is important and usually acts as backbone of an application running on production with continuous deployment and integration. It helps to increase efficiency of a software development team. But, how can we take advantage golang and its various available tools to make it better and efficient?
Notes
This talk is on using golang and its various tools to help automate an app from development to production. Basically, an automated pipeline with golang and it’s tools. Besides, an exploration of how to improve and make this pipeline more efficient and fully automated.
A talk on how garbage collection plays an important role and how the efficiency of garbage collection benefits running an application with slight comparison with ruby’s garbage collection.
Description
Someone need to work extra hard and clean up the mess. That job often falls on the efficiency of garbage collection. But, what makes it efficient and how does this helps to improve our application. The story of garbage collection with slight comparison with Ruby’s garbage collection.
Notes
I’m new to talking at conference and believe this will be a good opportunity for me. Plus, I love golang. :)
Blockchains are the hot new thing that everyone’s talking about, but nobody uses. This talk covers a key challenge in the blockchain space — scaling — through the perspective of two Go projects. Come learn about the state of blockchain scaling, and the features & limits of Go in the space.
Description
How do you scale a public, decentralized network? This talk explores two projects that approach scaling blockchain networks to support high transaction throughput with fast settlement times. We’ll walk through an overview of payment channels and sidechains before diving into the implementation of the Starlight and Slidechain projects in Go. This will be a chance to learn more about building blockchain projects in Go, and to explore the challenges of scaling blockchains.
An application spawning a million of threads! yes. It is possible, in Go. How does Go achieve massive concurrency and still acts frugally with system resources? That is the topic of discussion for this talk. It will explore Go runtime, threading model, design decisions, and scheduling paradigms.
Description
Concurrency is one of the most exciting features of Go language. A single threaded program runs serially, but if you have tasks that can run concurrently, you create threads for such tasks. Go supports creation of thousands of threads in an application! But how does that happen? It’s all in Go’s runtime. Go runtime maximise CPU utilisation, minimises latencies and memory footprint.
This talk discusses fundamentals of Go scheduler, how Go provides concurrency for Goroutines and secrets of massive concurrency.
Notes
My experience of 14 years has been into system software, distributed systems, cloud storage systems and file systems. My development languages are Golang, C/C++ and Python.
I have been a speaker at Python language conferences, PyCon APAC, PyCon NZ and PyCon India. I’ve also been a speaker at [redacted].
61. Do less: Building simple distributed systems using NATS messaging
Abstract
Addressing and communicating securely within a modern distributed system architecture can be complex when the design depends too closely on IP networks. In this talk, we show how messaging based approaches can help abstract the network, and also enable more advanced communication patterns than RPC.
Description
One the biggest benefits of moving to containers is being able to use simple abstractions to reason about the workloads that compose or
distributed system, but still many architectures rely on dialing to multiple endpoints for communicating which result in very complex network topologies that can make a system harder to operate.
In this talk, you will learn how messaging techniques based architectures can help simplifying cloud native applications by abstracting the network as well as enabling more advanced communication patterns and how to implement load balancing, command & control, work scheduling, and low latency RPC using the NATS messaging system.
Notes
I’m one of the core maintainers of NATS and it can be a very lightweight option in comparison to other protocols or service mesh approaches, usually used for request/response based APIs, so in this talk we provide users unfamiliar with using messaging or considering alternative approaches how to develop apps using the feature set from the project which although minimal is very powerful (publish/subscribe, request/response and distributed queues).
Go is commonly used in the backend and as low as on single-board computers.
How about even lower to the world of resource-constrained microcontrollers? In my talk I’ll explore the use of Go with an Arduino-based robot.
Description
In this talk, I’ll run Go code on an Arduino to control a tracked robot to follow a line and more. This would be fairly easy to do on the native Arduino C code with the plenty of libraries. In the Go microcontroller world, this is obviously not the case so I’ll explore the challenges behind how to make it possible.
 .
.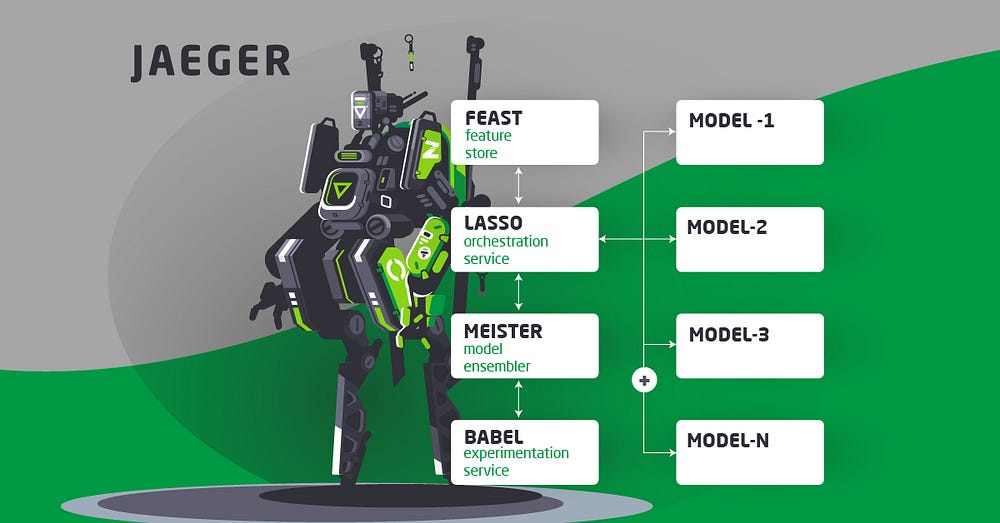{kind=link}